%%capture
!pip install -qU matplotlib rioxarray xrscipy supertree6 Classifications d’images supervisées
6.1 Préambule
Assurez-vous de lire ce préambule avant d’exécuter le reste du notebook.
6.1.1 Objectifs
Dans ce chapitre, nous ferons une introduction générale à l’apprentissage automatique et abordons quelques techniques fondamentales. La librairie centrale utilisée dans ce chapitre sera sickit-learn. Ce chapitre est aussi disponible sous la forme d’un notebook Python sur Google Colab:

Objectifs d’apprentissage visés dans ce chapitre
À la fin de ce chapitre, vous devriez être en mesure de :
- comprendre les principes de l’apprentissage automatique supervisé;
- mettre en place un pipeline d’entraînement;
- savoir comment évaluer les résultats d’un classificateur;
- visualiser les frontières de décision;
- mettre en place des techniques de classifications comme K-NN et les arbres de décision;
6.1.2 Librairies
Les librairies utilisées dans ce chapitre sont les suivantes :
Dans l’environnement Google Colab, seul rioxarray et xrscipy sont installés:
Vérifiez les importations nécessaires en premier:
import numpy as np
import rioxarray as rxr
from scipy import signal
import xarray as xr
import rasterio
import xrscipy
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
import geopandas
from shapely.geometry import Point
import pandas as pd
from numba import jit
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
from sklearn.metrics import confusion_matrix, classification_report, ConfusionMatrixDisplay
from sklearn.preprocessing import StandardScaler
from sklearn.inspection import DecisionBoundaryDisplay
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis, QuadraticDiscriminantAnalysis
from sklearn.datasets import make_blobs, make_classification, make_gaussian_quantiles6.1.3 Images utilisées
Nous utilisons les images suivantes dans ce chapitre:
%%capture
import gdown
gdown.download('https://drive.google.com/uc?export=download&confirm=pbef&id=1a6Ypg0g1Oy4AJt9XWKWfnR12NW1XhNg_', output= 'RGBNIR_of_S2A.tif')
gdown.download('https://drive.google.com/uc?export=download&confirm=pbef&id=1a4PQ68Ru8zBphbQ22j0sgJ4D2quw-Wo6', output= 'landsat7.tif')
gdown.download('https://drive.google.com/uc?export=download&confirm=pbef&id=1_zwCLN-x7XJcNHJCH6Z8upEdUXtVtvs1', output= 'berkeley.jpg')
gdown.download('https://drive.google.com/uc?export=download&confirm=pbef&id=1dM6IVqjba6GHwTLmI7CpX8GP2z5txUq6', output= 'SAR.tif')
gdown.download('https://drive.google.com/uc?export=download&confirm=pbef&id=1aAq7crc_LoaLC3kG3HkQ6Fv5JfG0mswg', output= 'carte.tif')Vérifiez que vous êtes capable de les lire :
with rxr.open_rasterio('berkeley.jpg', mask_and_scale= True) as img_rgb:
print(img_rgb)
with rxr.open_rasterio('RGBNIR_of_S2A.tif', mask_and_scale= True) as img_rgbnir:
print(img_rgbnir)
with rxr.open_rasterio('SAR.tif', mask_and_scale= True) as img_SAR:
print(img_SAR)
with rxr.open_rasterio('carte.tif', mask_and_scale= True) as img_carte:
print(img_carte)6.2 Principes généraux
Une classification supervisée ou dirigée consiste à attribuer une étiquette (une classe) de manière automatique à chaque point d’un jeu de données. Cette classification peut se faire à l’aide d’une cascade de règles pré-établies (arbre de décision) ou à l’aide de techniques d’apprentissage automatique (machine learning). L’utilisation de règles pré-établies atteint vite une limite car ces règles doivent être fournies manuellement par un expert. Ainsi, l’avantage de l’apprentissage automatique est que les règles de décision sont dérivées automatiquement du jeu de données via une phase dite d’entraînement. On parle souvent de solutions générées par les données (Data Driven Solutions). Cet ensemble de règles est souvent appelé modèle. On visualise souvent ces règles sous la forme de frontières de décisions dans l’espace des données. Cependant, un des défis majeurs de ce type de technique est d’être capable de produire des règles qui soient généralisables au-delà du jeu d’entraînement.
Les classifications supervisées ou dirigées présupposent donc que nous avons à disposition un jeu d’entraînement déjà étiqueté. Celui-ci va nous permettre de construire un modèle. Afin que ce modèle soit représentatif et robuste, il nous faut assez de données d’entraînement. Les algorithmes d’apprentissage automatique sont très nombreux et plus ou moins complexes pouvant produire des frontières de décision très complexes et non linéaires.
6.2.1 Comportement d’un modèle
Cet exemple tiré de sickit-learn illustre les problèmes d’ajustement insuffisant ou sous-apprentissage (underfitting) et d’ajustement excessif ou sur-apprentissage (overfitting) et montre comment nous pouvons utiliser la régression linéaire avec un modèle polynomiale pour approximer des fonctions non linéaires. La figure 6.1 montre la fonction que nous voulons approximer, qui est une partie de la fonction cosinus (couleur orange). En outre, les échantillons de la fonction réelle et les approximations de différents modèles sont affichés en bleu. Les modèles ont des caractéristiques polynomiales de différents degrés. Nous pouvons constater qu’une fonction linéaire (polynôme de degré 1) n’est pas suffisante pour s’adapter aux échantillons d’apprentissage. C’est ce qu’on appelle un sous-ajustement (underfitting) qui produit un biais systématique quels que soient les points d’entraînement. Un polynôme de degré 4 se rapproche presque parfaitement de la fonction réelle. Cependant, pour des degrés plus élevés, le modèle s’adaptera trop aux données d’apprentissage, c’est-à-dire qu’il apprendra le bruit des données d’apprentissage. Nous évaluons quantitativement le sur-apprentissage et le sous-apprentissage à l’aide de la validation croisée. Nous calculons l’erreur quadratique moyenne (EQM) sur l’ensemble de validation. Plus elle est élevée, moins le modèle est susceptible de se généraliser correctement à partir des données d’apprentissage.
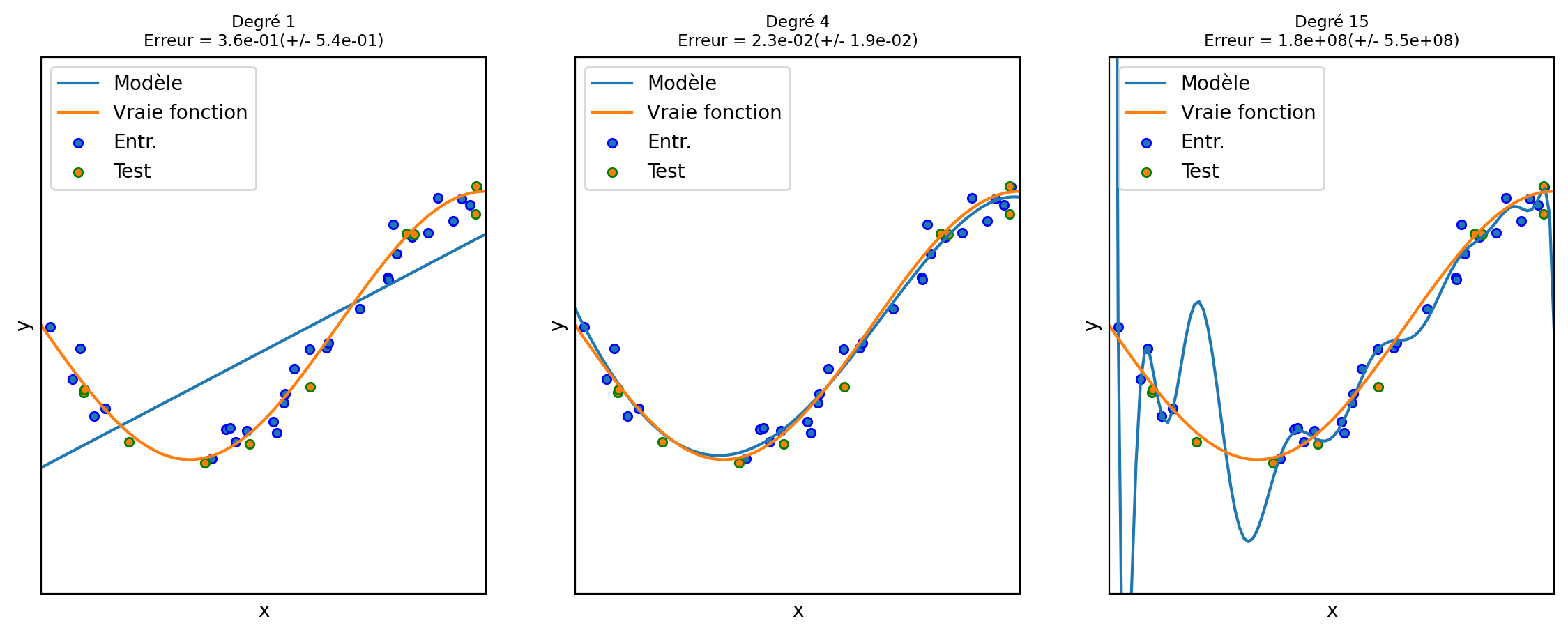
On constate aussi que sans les échantillons de validation, nous serions incapables de déterminer la situation de sur-apprentissage, l’erreur sur les points d’entraînement seuls étant excellente pour un degré 15.
6.2.2 Pipeline
La construction d’un modèle implique généralement toujours les mêmes étapes illustrées sur la figure 6.2:
La préparation des données implique parfois un pré-traitement afin de normaliser les données.
Partage des données en trois groupes: entraînement, validation et test.
L’apprentissage du modèle sur l’ensemble d’entraînement. Cet apprentissage nécessite de déterminer les valeurs des hyper-paramètres du modèle par l’usager.
La validation du modèle sur l’ensemble de validation. Cette étape vise à vérifier que les hyper-paramètres du modèle sont adéquats.
Enfin le test du modèle sur un ensemble de données indépendant.
flowchart TD
A[fa:fa-database Données] --> B(fa:fa-gear Prétraitement)
B --> C(fa:fa-folder-tree Partage des données) -.-> D(fa:fa-gears Entraînement)
H[[Hyper-paramètres]] --> D
D --> |Modèle| E>Validation]
E --> |Modèle| G>Test]
C -.-> E
C -.-> G
6.2.3 Construction d’un ensemble d’entraînement
Les données d’entraînement permettent de construire un modèle. Elles peuvent prendre des formes très variées mais on peut voir cela sous la forme d’un tableau \(N \times D\):
La taille \(N\) du jeu de données.
Chaque entrée définit un échantillon ou un point dans un espace à plusieurs dimensions.
Chaque échantillon est décrit par \(D\) dimensions ou caractéristiques (features).
Une façon simple de construire un ensemble d’entraînement est d’échantillonner un produit existant. Nous utilisons une carte d’occupation des sols qui contient 12 classes différentes.
couleurs_classes= {'NoData': 'black', 'Commercial': 'yellow', 'Nuages': 'lightgrey',
'Foret': 'darkgreen', 'Faible_végétation': 'green', 'Sol_nu': 'saddlebrown',
'Roche': 'dimgray', 'Route': 'red', 'Urbain': 'orange', 'Eau': 'blue', 'Tourbe': 'salmon', 'Végétation éparse': 'darkgoldenrod', 'Roche avec végétation': 'darkseagreen'}
nom_classes= [*couleurs_classes.keys()]
couleurs_classes= [*couleurs_classes.values()]On peut visualiser la carte de la façon suivante :
import matplotlib.pyplot as plt
import rioxarray as rxr
cmap_classes = ListedColormap(couleurs_classes)
fig, ax = plt.subplots(nrows=1, ncols=1, figsize=(8, 6))
img_carte.squeeze().plot.imshow(cmap=cmap_classes, vmin=0, vmax=12)
ax.set_title("Carte d'occupation des sols", fontsize="small")Text(0.5, 1.0, "Carte d'occupation des sols")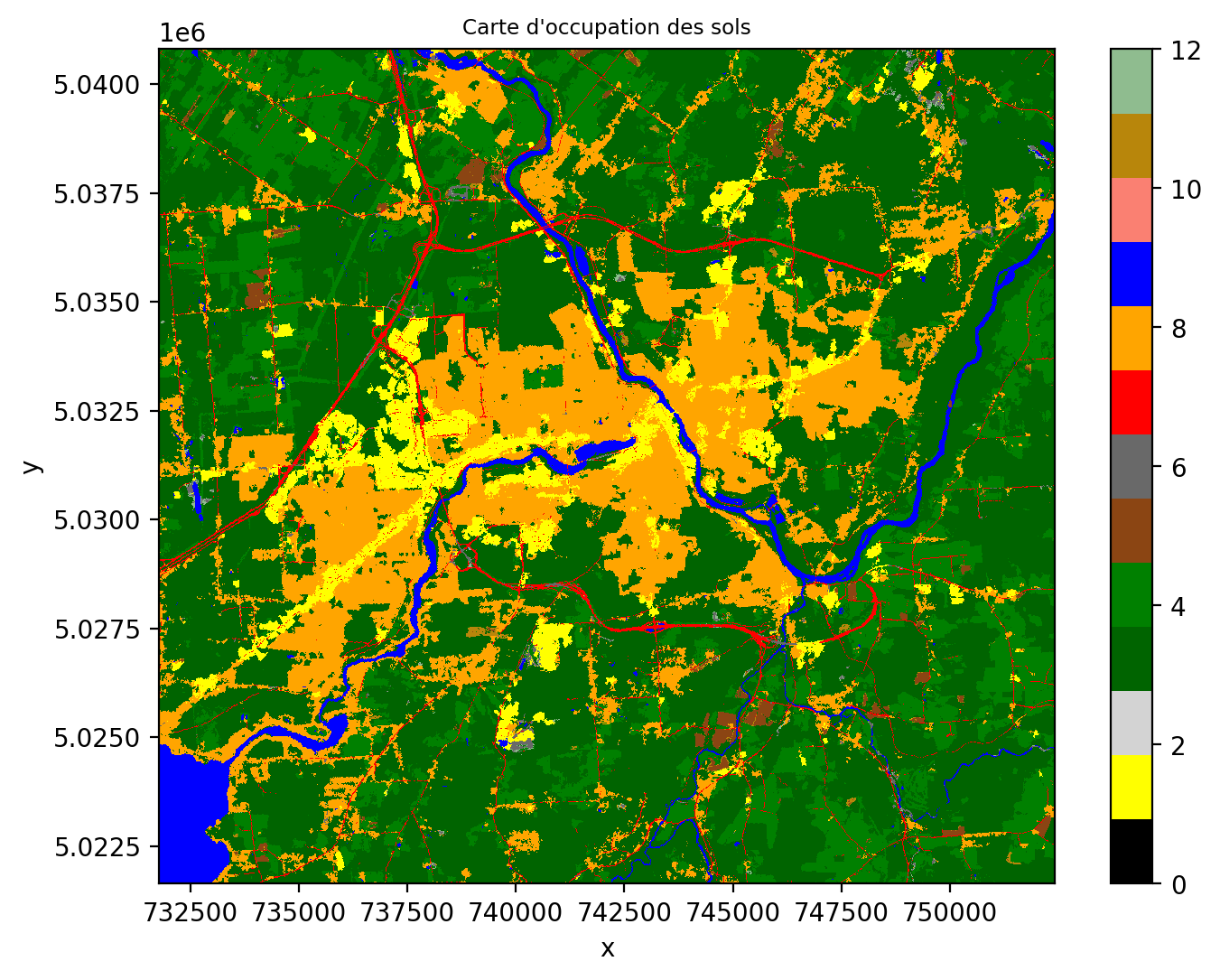
On peut facilement calculer la fréquence d’occurrences des 12 classes dans l’image à l’aide de numpy:
img_carte= img_carte.squeeze() # nécessaire pour ignorer la dimension du canal
compte_classe = np.unique(img_carte.data, return_counts=True)
print(compte_classe)(array([ 1., 3., 4., 5., 6., 7., 8., 9., 11., 12., nan],
dtype=float32), array([ 193558, 2104777, 670158, 29523, 14624, 94751, 750046,
123671, 9079, 4327, 10]))La fréquence d’apparition de chaque classe varie grandement, on parle alors d’un ensemble déséquilibré. Ceci est très commun dans la plupart des ensembles d’entraînement, puisque les classes ont très rarement la même fréquence. Par exemple, à la lecture du graphique en barres verticales, on constate que la classe forêt est très présentes contrairement à plusieurs autres classes (notamment, tourbe, végétation éparse, roche, sol nu et nuages).
valeurs, comptes = compte_classe
# Create the histogram
plt.figure(figsize=(5, 3))
plt.bar(valeurs, comptes/comptes.sum()*100)
plt.xlabel("Classes")
plt.ylabel("%")
plt.title("Fréquences des classes", fontsize="small")
plt.xticks(range(len(nom_classes)), nom_classes, rotation=45, ha='right')
plt.show()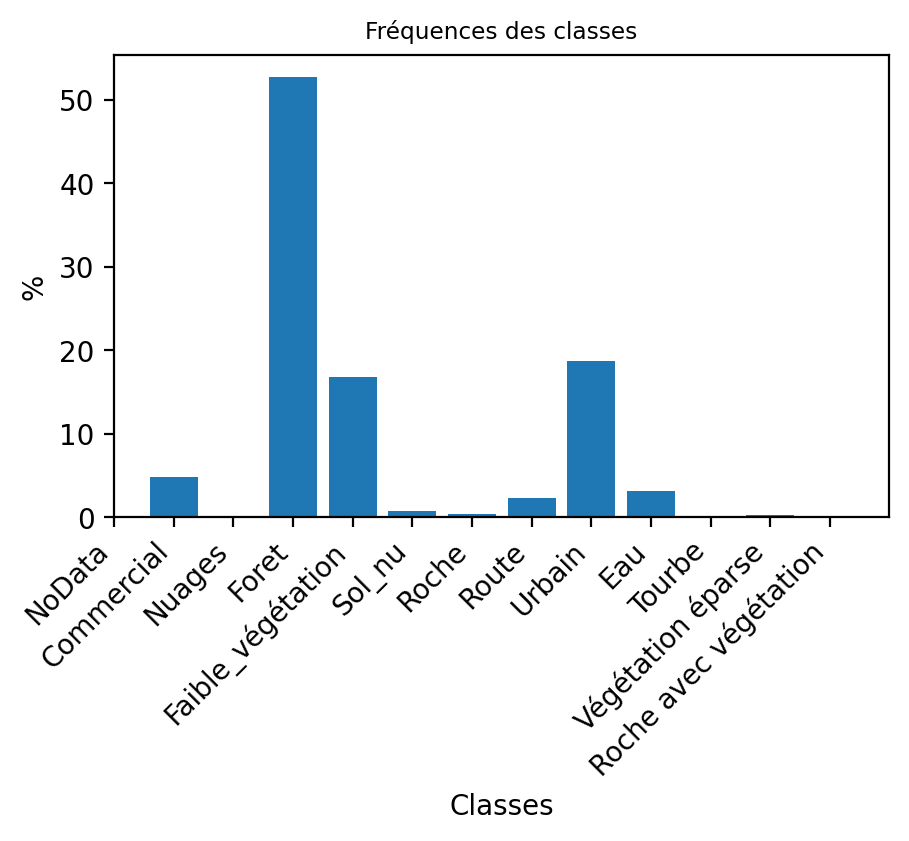
On peut échantillonner aléatoirement 100 points pour chaque classe:
img_carte= img_carte.squeeze()
class_counts = np.unique(img_carte.data, return_counts=True)
# Liste vide des points échantillonnées
sampled_points = []
class_labels= [] # contient les étiquettes des classes
for class_label in range(1,13): # pour chacune des 12 classes
# On cherche tous les pixels pour cette étiquette
class_pixels = np.argwhere(img_carte.data == class_label)
# On se limite à 100 pixels par classe
n_samples = min(100, len(class_pixels))
# On les choisit les positions aléatoirement
np.random.seed(0) # ceci permet de répliquer le tirage aléatoire
sampled_indices = np.random.choice(len(class_pixels), n_samples, replace=False)
# On prends les positions en lignes, colonnes
sampled_pixels = class_pixels[sampled_indices]
# On ajoute les points à la liste
sampled_points.extend(sampled_pixels)
class_labels.extend(np.array([class_label]*n_samples)[:,np.newaxis])
# Conversion en NumPy array
sampled_points = np.array(sampled_points)
class_labels = np.array(class_labels)
# On peut naviguer les points à l'aide de la géoréférence
transformer = rasterio.transform.AffineTransformer(img_carte.rio.transform())
transform_sampled_points= transformer.xy(sampled_points[:,0], sampled_points[:,1])
fig, ax = plt.subplots(nrows=1, ncols=1, figsize=(8, 6))
img_carte.squeeze().plot.imshow(cmap=cmap_classes, vmin=0, vmax=12)
ax.scatter(transform_sampled_points[0], transform_sampled_points[1], c='w', s=1) # Plot sampled points
ax.set_title("Carte d'occupation des sols avec les points échantillonnés", fontsize="small")
plt.show()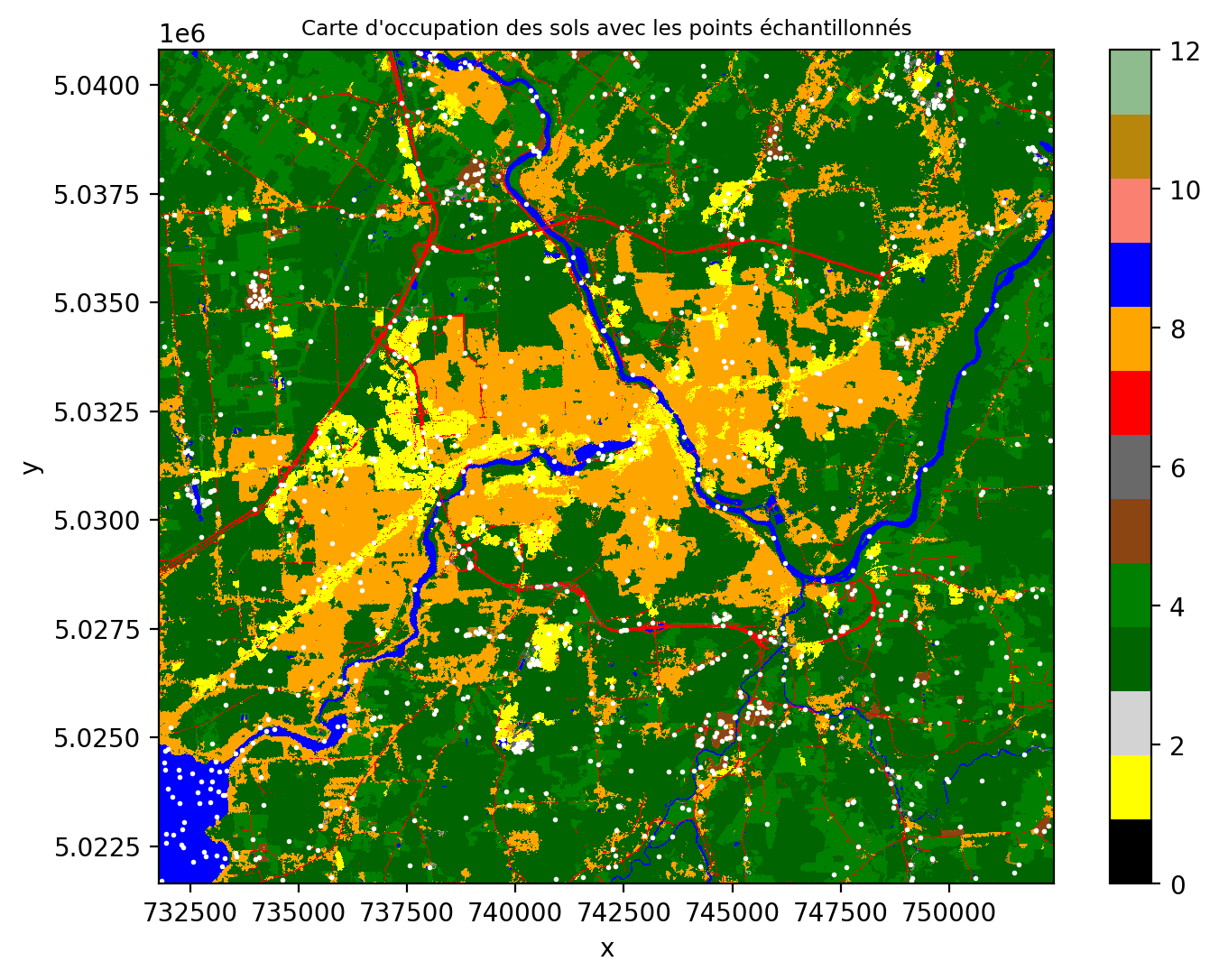
Une fois les points sélectionnés, on ajoute les valeurs des bandes provenant d’une image satellite. Pour cela, on utilise la méthode sample() de rasterio. Éventuellement, la librairie geopandas permet de gérer les données d’entraînement sous la forme d’un tableau transportant aussi l’information de géoréférence. Afin de pouvoir classifier ces points, on ajoute les valeurs radiométriques provenant de l’image Sentinel-2 à 4 bandes RGBNIR_of_S2A.tif. Ces valeurs seront stockées dans la colonne value sous la forme d’un vecteur en format string :
points = [Point(xy) for xy in zip(transform_sampled_points[0], transform_sampled_points[1])]
gdf = geopandas.GeoDataFrame(range(1,len(points)+1), geometry=points, crs=img_carte.rio.crs)
coord_list = [(x, y) for x, y in zip(gdf["geometry"].x, gdf["geometry"].y)]
with rasterio.open('RGBNIR_of_S2A.tif') as src:
gdf["value"] = [x for x in src.sample(coord_list)]
gdf['class']= class_labels
gdf.to_csv('sampling_points.csv') # sauvegarde sous forme d'un format csv
gdf.head()| 0 | geometry | value | class | |
|---|---|---|---|---|
| 0 | 1 | POINT (740369.77 5032078.683) | [1894, 1994, 2112, 2318] | 1 |
| 1 | 2 | POINT (737542.924 5031770.119) | [1440, 1650, 1449, 5021] | 1 |
| 2 | 3 | POINT (736726.722 5031411.786) | [1666, 1972, 1819, 3437] | 1 |
| 3 | 4 | POINT (736816.305 5027470.128) | [1858, 2078, 2190, 2436] | 1 |
| 4 | 5 | POINT (736746.629 5031362.018) | [2194, 2304, 2268, 3075] | 1 |
6.3 Analyse préliminaire des données
Une bonne pratique avant d’appliquer une technique d’apprentissage automatique est de regarder les caractéristiques de vos données:
Le nombre de dimensions (features).
Certaines dimensions sont informatives (discriminantes) et d’autres ne le sont pas.
Le nombre classes.
Le nombre de modes (clusters) par classes.
Le nombre d’échantillons par classe.
La forme des groupes.
La séparabilité des classes ou des groupes.
Une manière d’évaluer la séparabilité de vos classes est d’appliquer des modèles Gaussiens sur chacune des classes. Le modèle Gaussien multivarié suppose que les données sont distribuées comme un nuage de points symétrique et unimodale. La distribution d’un point \(x\) appartenant à la classe \(i\) est la suivante:
\[ P(x | Classe=i) = \frac{1}{(2\pi)^{D/2} |\Sigma_i|^{1/2}}\exp\left(-\frac{1}{2} (x-m_i)^t \Sigma_k^{-1} (x-m_i)\right) \]
La méthode QuadraticDiscriminantAnalysis permet de calculer les paramètres des Gaussiennes multivariées pour chacune des classes.
On peut calculer une distance entre deux nuages Gaussiens avec la distance dites de Jeffries-Matusita (JM) basée sur la distance de Bhattacharyya \(B\) (Jensen 2016):
\[ \begin{aligned} JM_{ij} &= 2(1 - e^{-B_{ij}}) \\ B_{ij} &= \frac{1}{8}(m_i - m_j)^t \left( \frac{\Sigma_i + \Sigma_j}{2} \right)^{-1} (m_i - m_j) + \frac{1}{2} \ln \left( \frac{|(\Sigma_i + \Sigma_j)/2|}{|\Sigma_i|^{1/2} |\Sigma_j|^{1/2}} \right) \end{aligned} \]
Cette distance présuppose que chaque classe \(i\) est décrite par son centre \(m_i\) et de sa dispersion dans l’espace à \(D\) dimensions mesurée par la matrice de covariance \(\Sigma_i\). On peut en faire facilement une fonction Python à l’aide de numpy:
def bhattacharyya_distance(m1, s1, m2, s2):
# Calcul de la covariance moyenne
s = (s1 + s2) / 2
# Calcul du premier terme (différence des moyennes)
m_diff = m1 - m2
term1 = np.dot(np.dot(m_diff.T, np.linalg.inv(s)), m_diff) / 8
# Calcul du second terme (différence de covariances)
term2 = 0.5 * np.log(np.linalg.det(s) / np.sqrt(np.linalg.det(s1) * np.linalg.det(s2)))
return term1 + term2
def jeffries_matusita_distance(m1, s1, m2, s2):
B = bhattacharyya_distance(m1, s1, m2, s2)
return 2 * (1 - np.exp(-B))La figure ci-dessous illustre différentes situations avec des données simulées ainsi que les distances JM correspondantes :
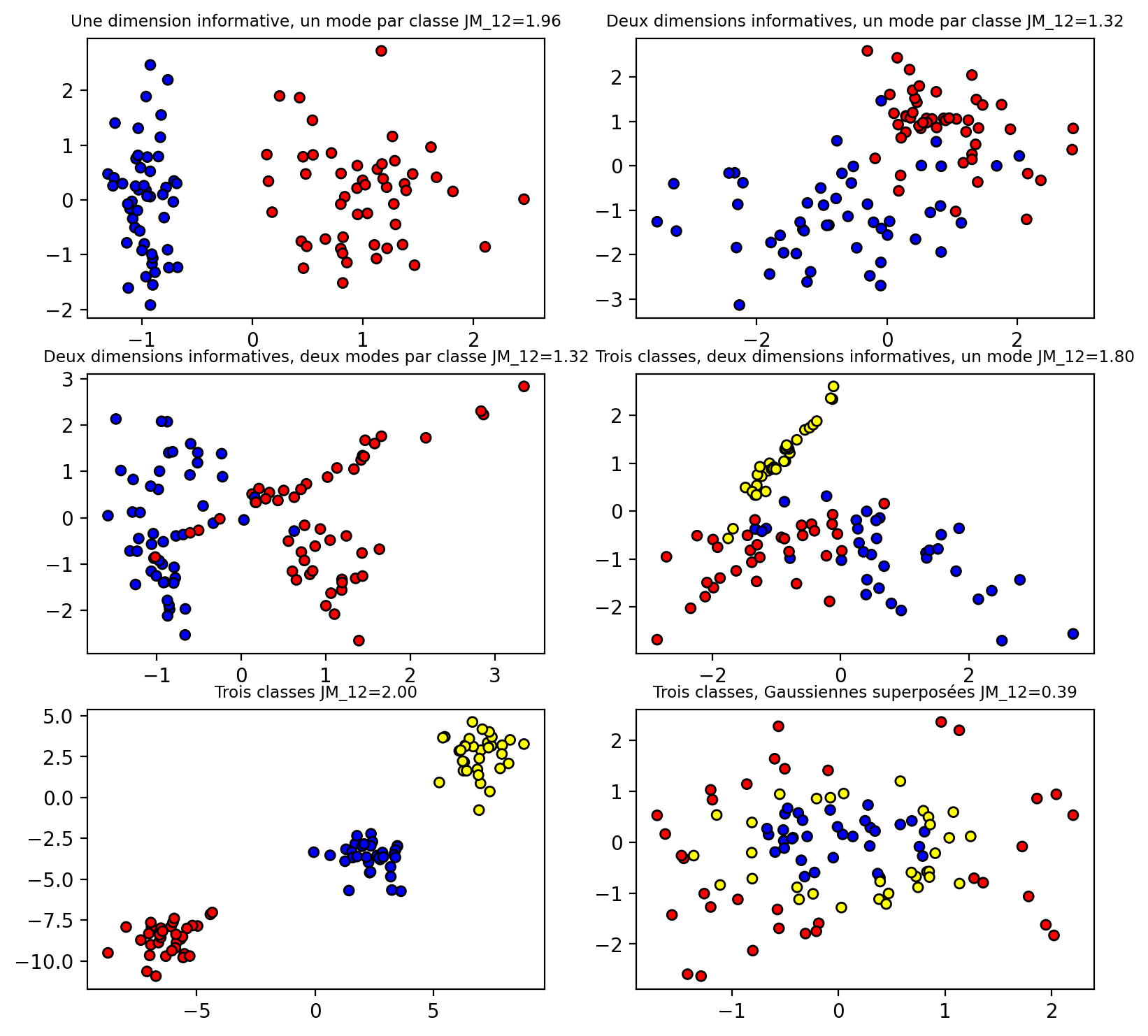
On forme notre ensemble d’entrainement à partir du fichier csv de la section Section 6.2.3.
df= pd.read_csv('sampling_points.csv')
# Extraire la colonne 'value'.
# 'value' est une chaîne de caractères représentation d'une liste de nombres.
# Nous devons la convertir en données numériques réelles.
X = df['value'].apply(lambda x: np.fromstring(x[1:-1], dtype=float, sep=' ')).to_list()
# on obtient une liste de numpy array qu'il faut convertir en un numpy array 2D
X= np.array([row.tolist() for row in X])
idx= X.sum(axis=-1)>0 # on exclut certains points sans valeurs
X= X[idx,...]
y = df['class'].to_numpy()
y= y[idx]
class_labels = np.unique(y).tolist() # on cherche à savoir combien de classes uniques
n_classes = len(class_labels)
if max(class_labels) > n_classes: # il se peut que certaines classes soit absentes
y_new= []
for i,l in enumerate(class_labels):
y_new.extend([i]*sum(y==l))
y_new = np.array(y_new)
couleurs_classes2= [couleurs_classes[c] for c in np.unique(y).tolist()] # couleurs des classes
nom_classes2= [nom_classes[c] for c in np.unique(y).tolist()]
cmap_classes2 = ListedColormap(couleurs_classes2)On peut faire une analyse de séparabilité sur notre ensemble d’entrainement de 10 classes. On obtient un tableau symmétrique de 10x10 valeurs. On observe des valeurs inférieures à 1, indiquant des séparabilités faibles entre ces classes sous l’hypothèse du modèle Gaussien:
qda= QuadraticDiscriminantAnalysis(store_covariance=True)
qda.fit(X, y_new) # calcul des paramètres des distributions Gaussiennes
JM= []
classes= np.unique(y_new).tolist() # étiquettes uniques des classes
for cl1 in classes:
for cl2 in classes:
JM.append(jeffries_matusita_distance(qda.means_[cl1], qda.covariance_[cl1], qda.means_[cl2], qda.covariance_[cl2]))
JM= np.array(JM).reshape(len(classes),len(classes))
JM= pd.DataFrame(JM, index=classes, columns=classes)
JM.head(10)| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.000000 | 1.931891 | 1.809590 | 1.761760 | 1.156486 | 1.326107 | 1.319344 | 1.830671 | 1.873676 | 1.700417 |
| 1 | 1.931891 | 0.000000 | 1.082978 | 0.918865 | 1.788737 | 1.527192 | 1.331400 | 1.901749 | 0.854802 | 1.133180 |
| 2 | 1.809590 | 1.082978 | 0.000000 | 0.266647 | 1.428062 | 1.255001 | 1.198888 | 1.947302 | 0.193032 | 0.782982 |
| 3 | 1.761760 | 0.918865 | 0.266647 | 0.000000 | 1.413401 | 1.219793 | 1.127950 | 1.929637 | 0.377379 | 0.840250 |
| 4 | 1.156486 | 1.788737 | 1.428062 | 1.413401 | 0.000000 | 0.397103 | 0.596618 | 1.956182 | 1.517926 | 1.036828 |
| 5 | 1.326107 | 1.527192 | 1.255001 | 1.219793 | 0.397103 | 0.000000 | 0.167221 | 1.976696 | 1.248383 | 0.660213 |
| 6 | 1.319344 | 1.331400 | 1.198888 | 1.127950 | 0.596618 | 0.167221 | 0.000000 | 1.956804 | 1.207618 | 0.660589 |
| 7 | 1.830671 | 1.901749 | 1.947302 | 1.929637 | 1.956182 | 1.976696 | 1.956804 | 0.000000 | 1.966022 | 1.886064 |
| 8 | 1.873676 | 0.854802 | 0.193032 | 0.377379 | 1.517926 | 1.248383 | 1.207618 | 1.966022 | 0.000000 | 0.741273 |
| 9 | 1.700417 | 1.133180 | 0.782982 | 0.840250 | 1.036828 | 0.660213 | 0.660589 | 1.886064 | 0.741273 | 0.000000 |
Afin d’évaluer chaque classe, on peut calculer la séparabilité minimale, ce qui nous permet de constater que la classe eau a le maximum de séparabilité avec les autres classes.
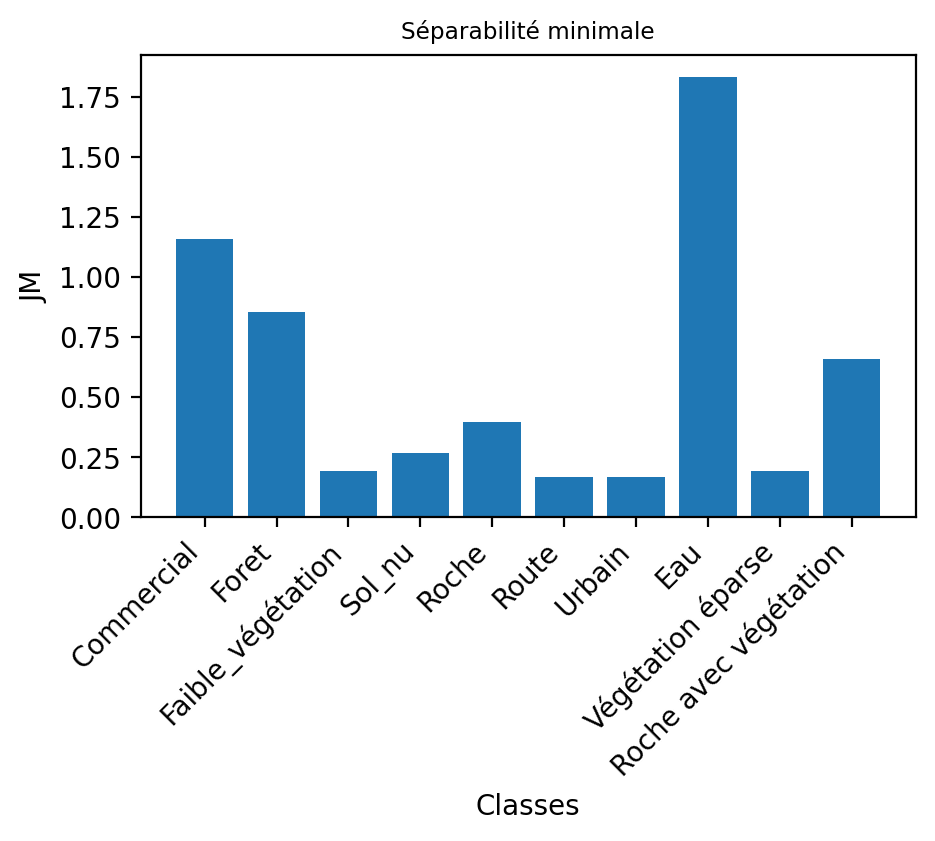
6.4 Mesures de performance d’une méthode de classification
Lorsque que l’on cherche à établir la performance d’un modèle, il convient de mesurer la performance du classificateur utilisé. Il existe de nombreuses mesures de performance qui sont toutes dérivées de la matrice de confusion. Cette matrice compare les étiquettes provenant de l’annotation (la vérité terrain) et les étiquettes prédites par un modèle. On peut définir \(C(i,j)\) comme étant le nombre de prédictions dont la vérité terrain indique la classe \(i\) qui sont prédites dans la classe \(j\). La fonction confusion_matrix permet de faire ce calcul, voici un exemple très simple:
y_true = ["cat", "ant", "cat", "cat", "ant", "bird", "bird"]
y_pred = ["ant", "ant", "cat", "cat", "ant", "cat", "bird"]
confusion_matrix(y_true, y_pred, labels=["ant", "bird", "cat"])array([[2, 0, 0],
[0, 1, 1],
[1, 0, 2]])La fonction classification_report permet de générer quelques métriques:
y_true = ["cat", "ant", "cat", "cat", "ant", "bird", "bird"]
y_pred = ["ant", "ant", "cat", "cat", "ant", "cat", "bird"]
print(classification_report(y_true, y_pred, target_names=["ant", "bird", "cat"])) precision recall f1-score support
ant 0.67 1.00 0.80 2
bird 1.00 0.50 0.67 2
cat 0.67 0.67 0.67 3
accuracy 0.71 7
macro avg 0.78 0.72 0.71 7
weighted avg 0.76 0.71 0.70 7
Le rappel (recall) pour une classe donnée est la proportion de la vérité terrain qui a été correctement identifiée et est sensible aux confusions entre classes (erreurs d’omission). Les valeurs de rappels correspondent à une normalisation de la matrice de confusion par rapport aux lignes.
\[ Recall_i= C_{ii} / \sum_j C_{ij} \] Une faible valeur de rappel signifie que le classificateur confond facilement la classe concernée avec d’autres classes.
La précision est la portion des prédictions qui ont été bien classifiées et est sensible aux fausses alarmes (erreurs de commission). Les valeurs de précision correspondent à une normalisation de la matrice de confusion par rapport aux colonnes. \[ Precision_i= C_{ii} / \sum_i C_{ij} \] Une faible valeur de précision signifie que le classificateur trouve facilement la classe concernée dans d’autres classes.
Le f1-score calcul une moyenne des deux métriques précédentes: \[
\text{f1-score}_i=2\frac{Recall_i \times Precision_i}{Recall_i + Precision_i}
\]
6.5 Méthodes non paramétriques
Les méthodes non paramétriques ne font pas d’hypothèses particulières sur les données. Un des inconvénients de ces modèles est que le nombre de paramètres du modèle augmente avec la taille des données.
6.5.1 Méthode des parallélépipèdes
La méthode du parallélépipède est probablement la plus simple et consiste à délimiter directement le domaine des points d’une classe par une boite (un parallélépipède) à \(D\) dimensions. Les limites de ces parallélépipèdes forment alors des frontières de décision manuelles qui permettent d’attribuer une classe d’appartenance à un nouveau point. Un des avantages de cette technique est que si un point n’est dans aucun parallélépipède alors il est non classifié. Par contre, la construction de ces parallélépipèdes se complexifient grandement avec le nombre de bandes. À une dimension, deux paramètres, équivalents à un seuillage d’histogramme, sont suffisants. À deux dimensions, vous devez définir 4 segments par classe. Avec trois bandes, vous devez définir six plans par classes et à D dimensions, D hyperplans à D-1 dimensions par classe. Le modèle ici est donc une suite de valeurs min et max pour chacune des bandes et des classes:
def parrallepiped_train(X_train, y_train):
classes= np.unique(y_train).tolist()
clf= []
for cl in classes:
data_cl= X_train[y_train == cl,...] # on cherche les données pour la classe courante
limits=[]
for b in range(data_cl.shape[1]):
limits.append([data_cl[:,b].min(), data_cl[:,b].max()]) # on calcul le min et max pour chaque bande
clf.append(np.array(limits))
return clf
clf= parrallepiped_train(X, y_new)La prédiction consiste à trouver pour chaque point la première limite qui est satisfaite. Notez qu’il n’y a aucun moyen de décider quelle est la meilleure classe si le point appartient à plusieurs classes.
@jit(nopython=True)
def parrallepiped_predict(clf, X_test):
y_pred= []
for data in X_test:
y_pred.append(np.nan)
for cl, limits in enumerate(clf):
inside= True
for b,limit in enumerate(limits):
inside = inside and (data[b] >= limit[0]) & (data[b] <= limit[1])
if ~inside:
break
if inside:
y_pred[-1]=cl
return np.array(y_pred)On peut appliquer ensuite le modèle sur l’image au complet. Les résultats sont assez mauvais, puisque seule la classe eau en bleu semble être bien classifiée.
data_image= img_rgbnir.to_numpy().transpose(1,2,0).reshape(img_rgbnir.shape[1]*img_rgbnir.shape[2],4)
y_image= parrallepiped_predict(clf, data_image)
y_image= y_image.reshape(img_rgbnir.shape[1],img_rgbnir.shape[2])
fig, ax = plt.subplots(nrows=1, ncols=1, figsize=(8, 6))
plt.imshow(y_image, cmap=cmap_classes2)
ax.set_title("Méthode des parrallélépipèdes", fontsize="small")
plt.show()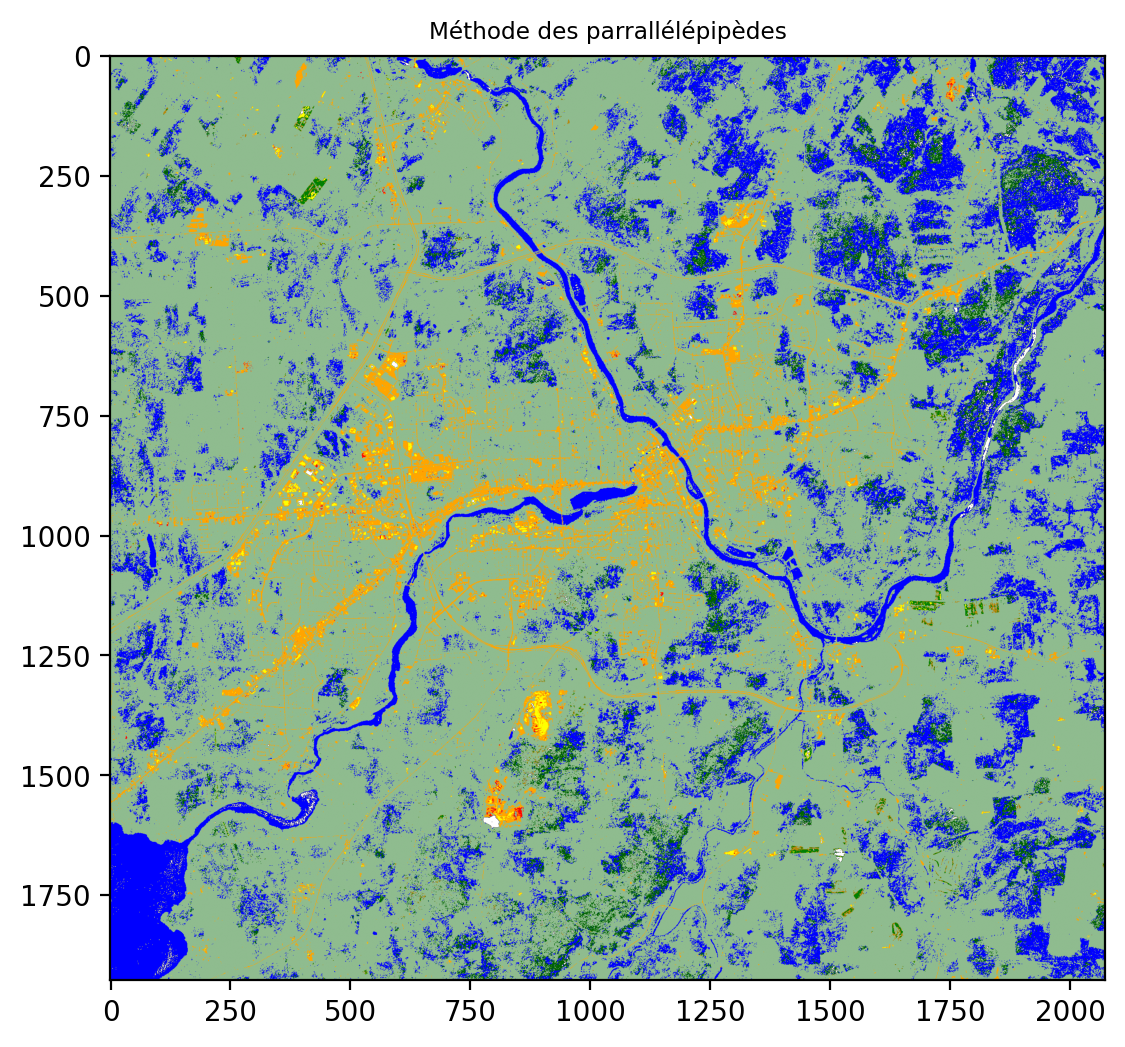
On peut calculer quelques mesures de performance sur l’ensemble d’entrainement :
y_pred= parrallepiped_predict(clf, X)
nom_classes2= [nom_classes[c] for c in np.unique(y).tolist()]
print(classification_report(y_new, y_pred, target_names=nom_classes2, zero_division=np.nan)) precision recall f1-score support
Commercial 1.00 0.06 0.11 100
Foret 1.00 0.09 0.17 100
Faible_végétation 1.00 0.02 0.04 100
Sol_nu nan 0.00 0.00 100
Roche 0.00 0.00 0.00 100
Route 0.00 0.00 0.00 100
Urbain 0.08 0.08 0.08 100
Eau 0.83 0.88 0.85 100
Végétation éparse 1.00 0.01 0.02 100
Roche avec végétation 0.13 1.00 0.23 100
accuracy 0.21 1000
macro avg 0.56 0.21 0.15 1000
weighted avg 0.56 0.21 0.15 1000
6.5.1.1 La malédiction de la haute dimension
Augmenter le nombre de dimension ou de caractéristiques des données permet de résoudre des problèmes complexes comme la classification d’image. Cependant, cela amène beaucoup de contraintes sur le volume des données. Supposons que nous avons N points occupant un segment linéaire de taille d. La densité de points est \(N/d\). Si nous augmentons le nombre de dimension D, la densité de points va diminuer exponentiellement en \(1/d^D\). Par conséquent, pour garder une densité constante et donc une bonne estimation des parallélépipèdes, il nous faudrait augmenter le nombre de points en puissance de D. Ceci porte le nom de la malédiction de la dimensionnalité (dimensionality curse). En résumé, l’espace vide augmente plus rapidement que le nombre de données d’entraînement et l’espace des données devient de plus en plus parcimonieux (sparse). Pour contrecarrer ce problème, on peut sélectionner les meilleures caractéristiques ou appliquer une réduction de dimension comme une ACP (Analyse en composantes principales).
6.5.2 Plus proches voisins
La méthode des plus proches voisins (K-Nearest-Neighbors) est certainement la plus simple des méthodes pour classifier des données. Elle consiste à comparer une nouvelle donnée avec ses voisins les plus proches en fonction d’une simple distance Euclidienne. Si une majorité de ces \(K\) voisins appartiennent à une classe majoritaire alors cette classe est sélectionnée. Afin de permettre un vote majoritaire, on choisira un nombre impair pour la valeur de \(K\). Mallgré sa simplicité, cette technique peut devenir assez demandante en temps de calcul pour un nombre important de points et un nombre élevé de dimensions.
Reprenons l’ensemble d’entraînement formé à partir de notre image RGBNIR précédente :
df= pd.read_csv('sampling_points.csv')
# Extraire la colonne 'value'.
# 'value' est une chaîne de caractères comme représentation d'une liste de valeurs.
# Nous devons la convertir en données numériques réelles.
X = df['value'].apply(lambda x: np.fromstring(x[1:-1], dtype=float, sep=' ')).to_list()
# on obtient une liste de numpy array qu'il faut convertir en un numpy array 2D
X= np.array([row.tolist() for row in X])
idx= X.sum(axis=-1)>0 # il se peut qu'il y ait des valeurs erronées
X= X[idx,...]
y = df['class'].to_numpy()
y= y[idx]
class_labels = np.unique(y).tolist() # on cherche à savoir combien de classes uniques
n_classes = len(class_labels)
if max(class_labels) > n_classes: # il se peut que certaines classes soit absentes
y_new= []
for i,l in enumerate(class_labels):
y_new.extend([i]*sum(y==l))
y_new = np.array(y_new)
nom_classes2= [nom_classes[c] for c in np.unique(y).tolist()]Il importe de préalablement centrer (moyenne = 0) et de réduire (variance = 1) les données avant d’appliquer la méthode K-NN; avec cette méthode de normalisation, on dit parfois que l’on blanchit les données. Puisque la variance de chaque dimension est égale à 1 (et donc l’inertie totale est égale au nombre de bandes), on s’assure qu’elle ait le même poids ait le même poids dans le calcul des distances entre points. Cette opération porte le nom de StandardScaler dans scikit-learn. On peut alors former un pipeline de traitement combinant les deux opérations :
clf = Pipeline(
steps=[("scaler", StandardScaler()), ("knn", KNeighborsClassifier(n_neighbors=1))]
)Avant d’effectuer un entraînement, on met généralement une portion des données pour valider les performances :
X_train, X_test, y_train, y_test = train_test_split(X, y_new, test_size=0.2, random_state=0)On peut visualiser les frontières de décision du K-NN pour différentes valeurs de \(K\) lorsque seulement deux bandes sont utilisées (Rouge et proche infra-rouge ici) :
Number of mislabeled points out of a total 200 points : 143
Number of mislabeled points out of a total 200 points : 141
Number of mislabeled points out of a total 200 points : 136
Number of mislabeled points out of a total 200 points : 130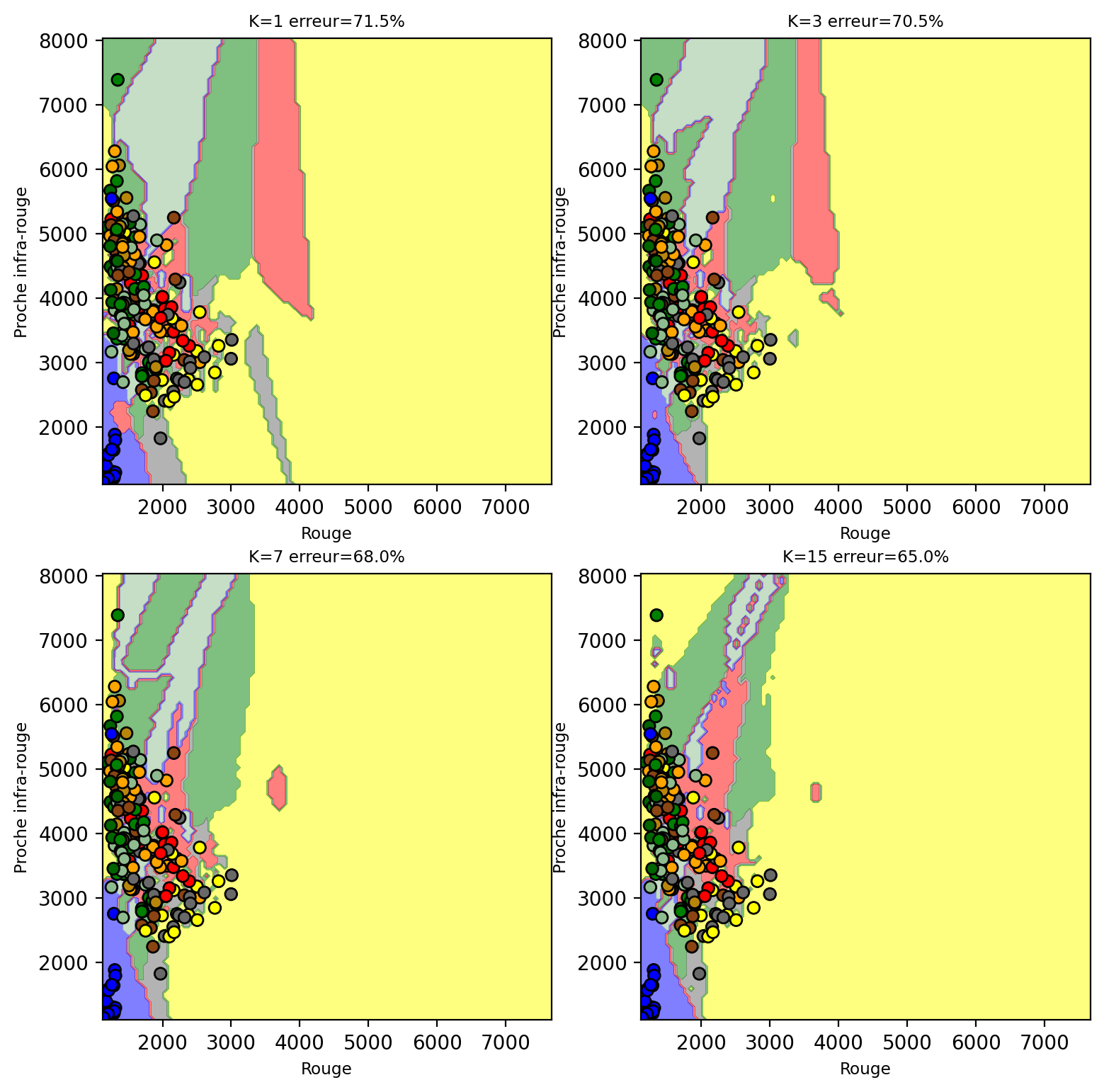
On peut voir comment les différentes frontières de décision se forment dans l’espace des bandes Rouge-NIR. L’augmentation de K rend ces frontières plus complexes et le calcul plus long.
clf.set_params(knn__weights='distance', knn__n_neighbors = 7).fit(X_train, y_train)
y_pred = clf.predict(X_test)
print("Nombre de points misclassifiés sur %d points : %d"
% (X_test.shape[0], (y_test != y_pred).sum()))Nombre de points misclassifiés sur 200 points : 117Le rapport de performance est le suivant :
nom_classes2= [nom_classes[c] for c in np.unique(y).tolist()]
print(classification_report(y_test, y_pred, target_names=nom_classes2, zero_division=np.nan)) precision recall f1-score support
Commercial 0.38 0.40 0.39 15
Foret 0.45 0.82 0.58 11
Faible_végétation 0.29 0.15 0.20 27
Sol_nu 0.53 0.45 0.49 22
Roche 0.38 0.26 0.31 23
Route 0.16 0.17 0.16 18
Urbain 0.25 0.20 0.22 20
Eau 0.96 0.96 0.96 24
Végétation éparse 0.26 0.53 0.35 15
Roche avec végétation 0.40 0.40 0.40 25
accuracy 0.41 200
macro avg 0.40 0.43 0.40 200
weighted avg 0.42 0.41 0.40 200
La matrice de confusion peut-être affichée de manière graphique :
disp= ConfusionMatrixDisplay.from_predictions(y_test, y_pred, display_labels=nom_classes2, xticks_rotation='vertical')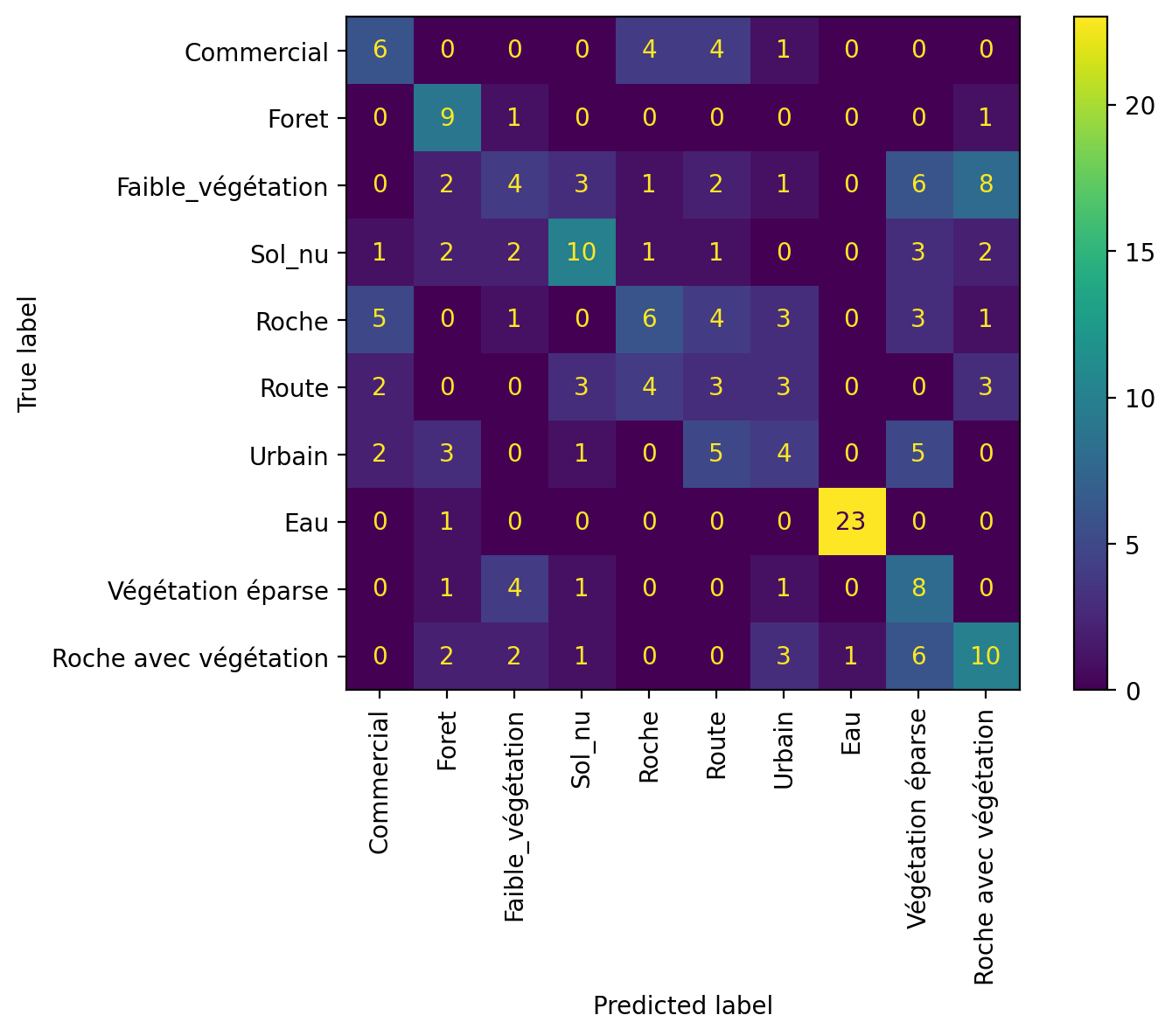
L’application du modèle (la prédiction) peut se faire sur toute l’image en transposant l’image sous forme d’une matrice avec Largeur x Hauteur lignes et 4 colonnes :
data_image= img_rgbnir.to_numpy().transpose(1,2,0).reshape(img_rgbnir.shape[1]*img_rgbnir.shape[2],4)
y_classe= clf.predict(data_image)
y_classe= y_classe.reshape(img_rgbnir.shape[1],img_rgbnir.shape[2])fig, ax = plt.subplots(nrows=1, ncols=1, figsize=(8, 6))
plt.imshow(y_classe, cmap=cmap_classes2)
ax.set_title("Carte d'occupation des sols avec K-NN", fontsize="small")
plt.show()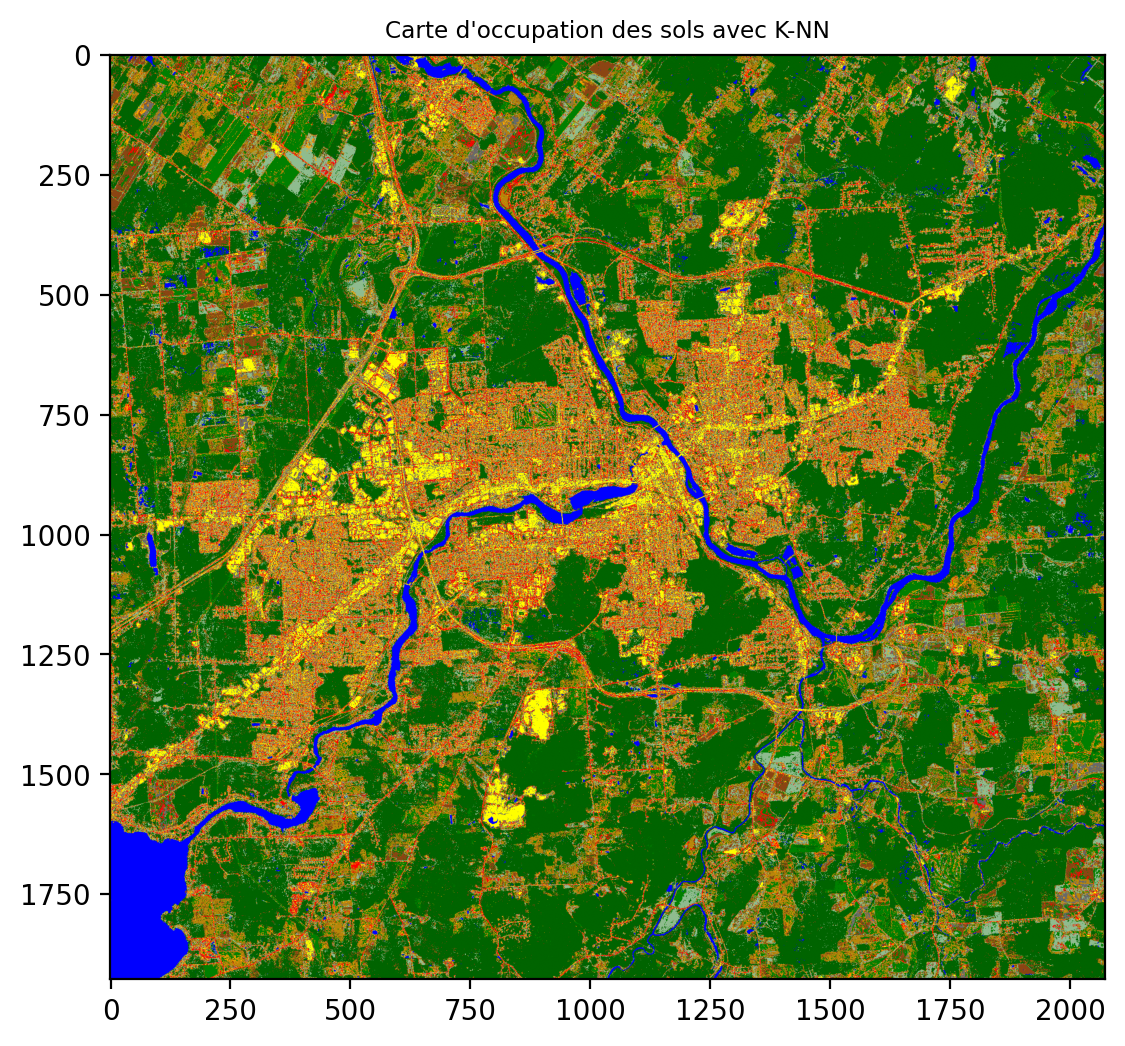
6.5.3 Méthodes par arbre de décision
La méthode par arbre de décision consiste à construire une cascade de règles de décision sur chaque caractéristique du jeu de donnée (Breiman et C. Stone 1984). On pourra trouver plus de détails dans la documentation de scikit-learn (Decision Trees). Les arbres de décision on tendance à surapprendre surtout si le nombre de dimensions est élevé. Il est donc conseillé d’avoir un bon ratio entre le nombre d’échantillons et le nombre de dimensions.
X_train, X_test, y_train, y_test = train_test_split(X, y_new, test_size=0.2, random_state=0)Number of mislabeled points out of a total 200 points : 167
Number of mislabeled points out of a total 200 points : 154
Number of mislabeled points out of a total 200 points : 143
Number of mislabeled points out of a total 200 points : 128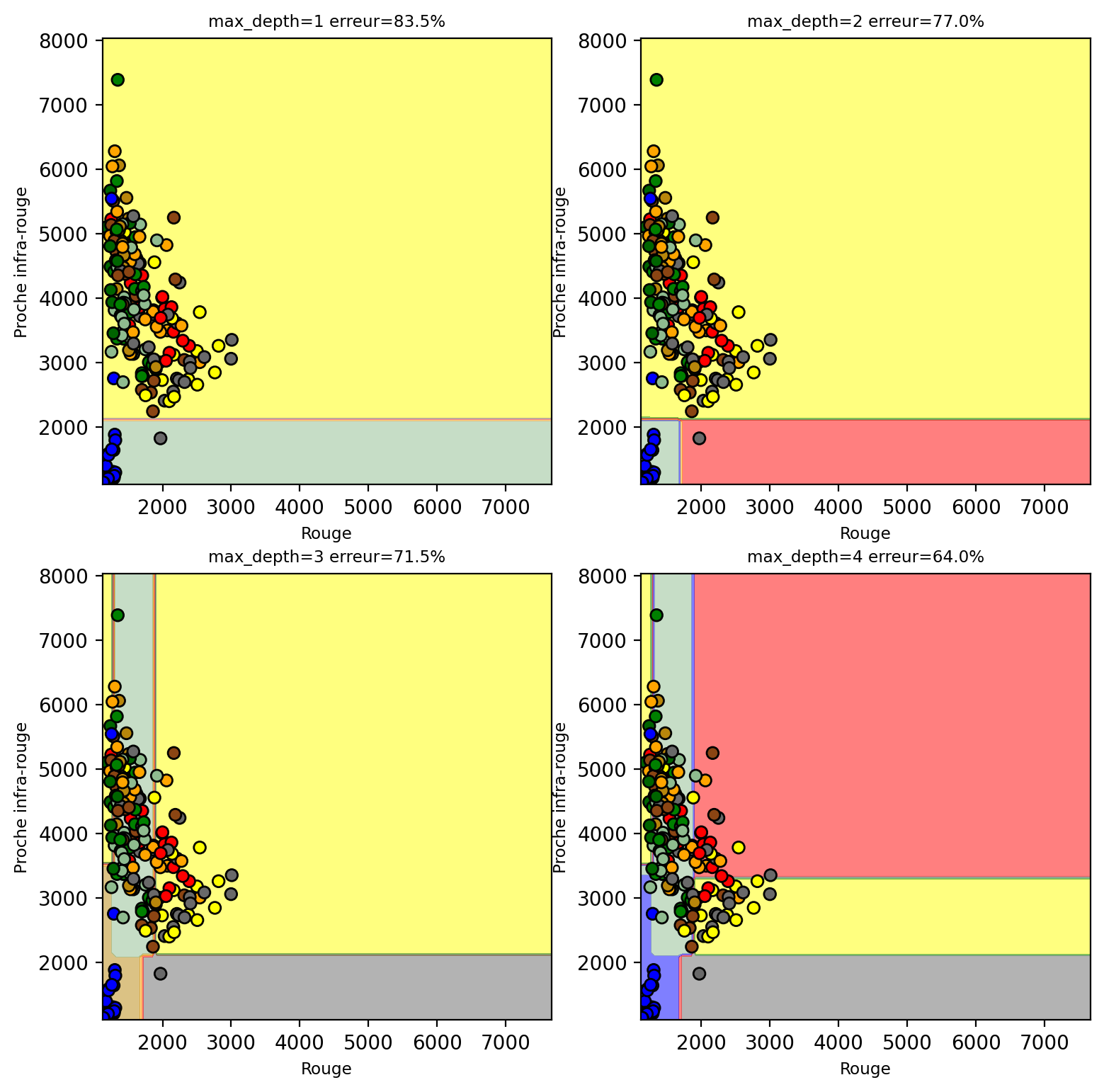
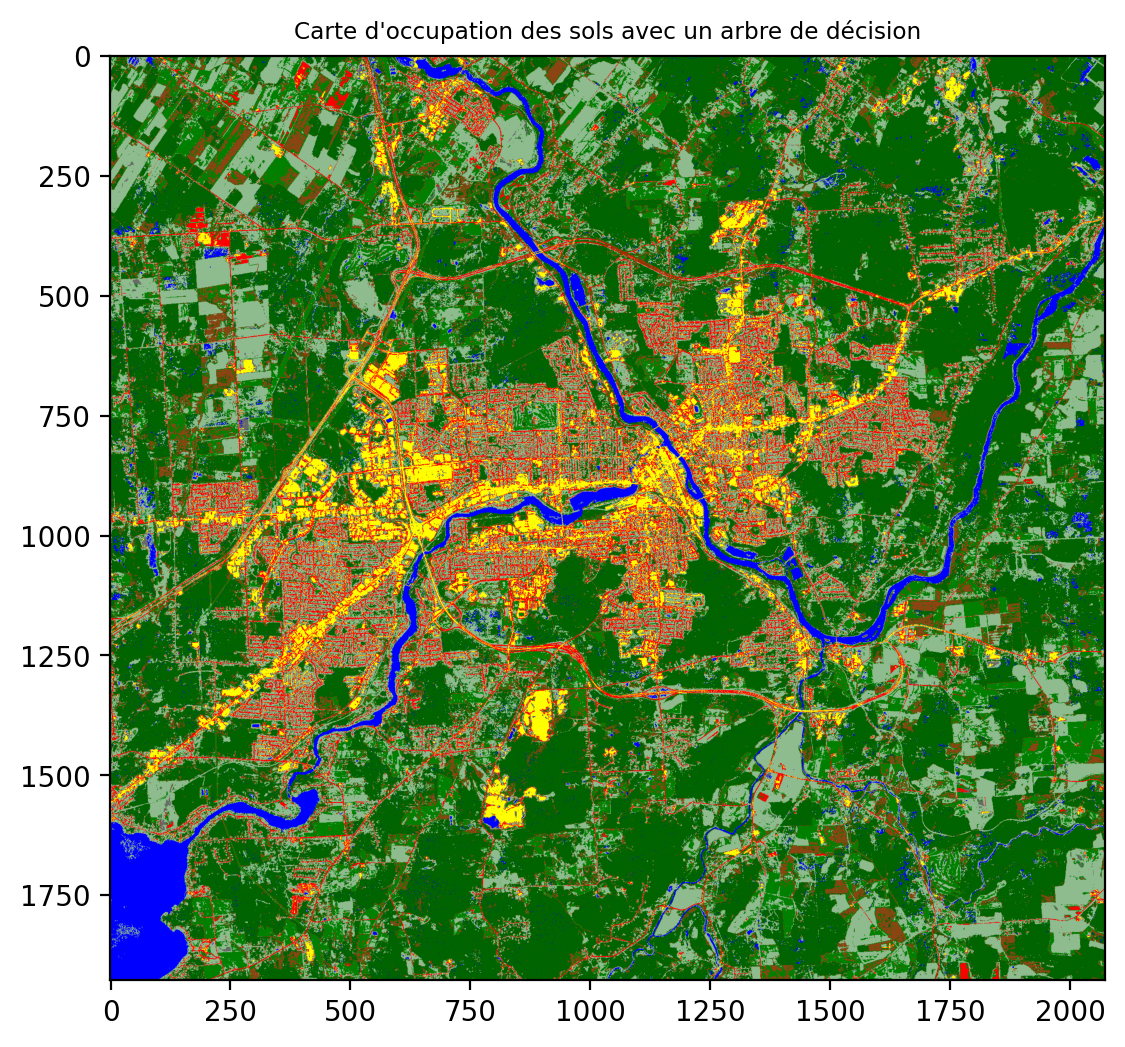
On peut observer que les frontières de décision sont formées d’un ensemble de plans simple. Chaque plan étant issu d’une règle de décison formé d’un seuil sur chacune des dimensions. On entraine un arbre de décision avec une profondeur maximale de 5:
clf = tree.DecisionTreeClassifier(max_depth=5)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print("Nombre de points misclassifiés sur %d points : %d"
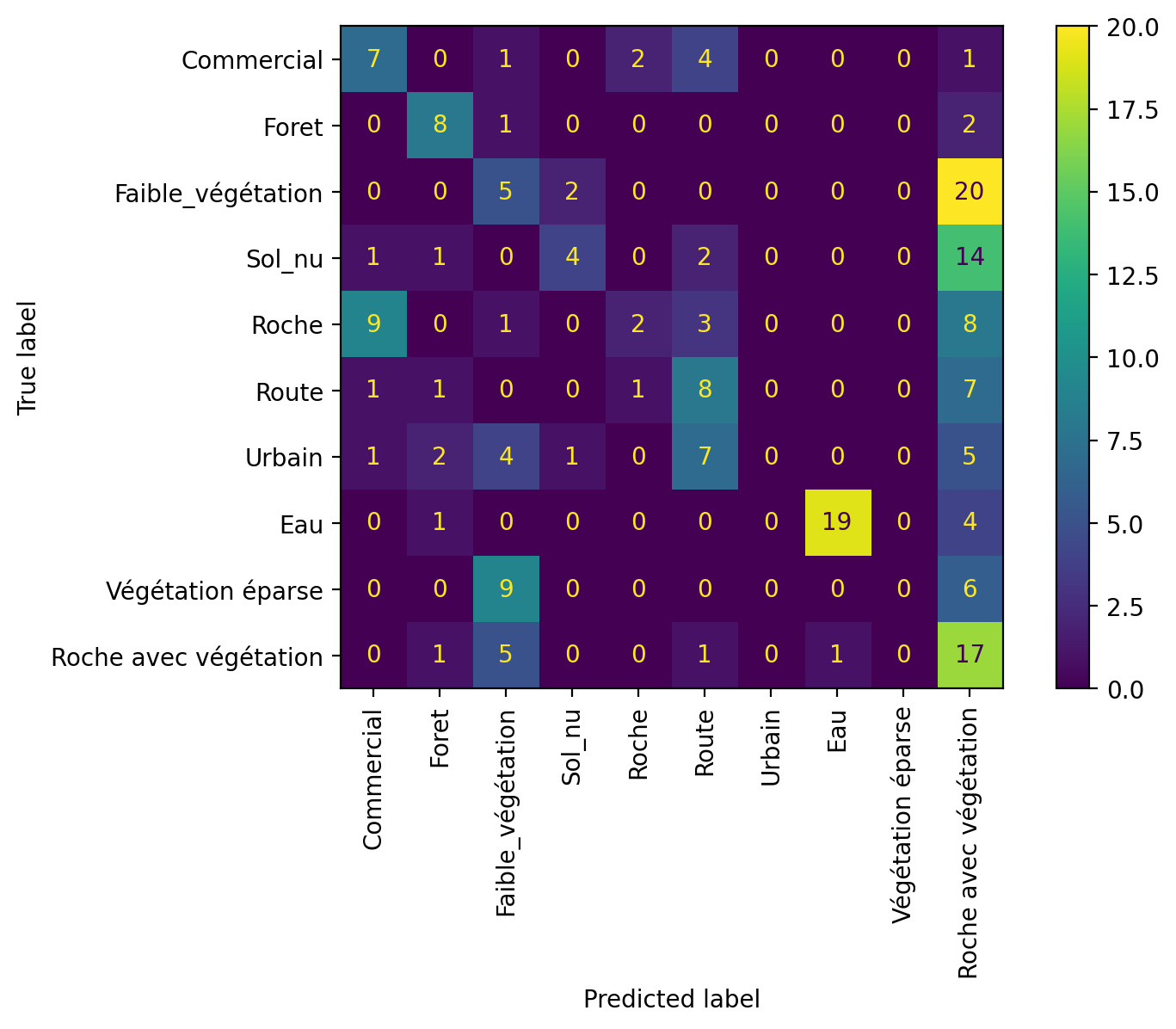
% (X_test.shape[0], (y_test != y_pred).sum()))Nombre de points misclassifiés sur 200 points : 130Le rapport de performance et la matrice de confusion:
precision recall f1-score support
Commercial 0.37 0.47 0.41 15
Foret 0.57 0.73 0.64 11
Faible_végétation 0.19 0.19 0.19 27
Sol_nu 0.57 0.18 0.28 22
Roche 0.40 0.09 0.14 23
Route 0.32 0.44 0.37 18
Urbain nan 0.00 0.00 20
Eau 0.95 0.79 0.86 24
Végétation éparse nan 0.00 0.00 15
Roche avec végétation 0.20 0.68 0.31 25
accuracy 0.35 200
macro avg 0.45 0.36 0.32 200
weighted avg 0.44 0.35 0.31 200
L’application du modèle (la prédiction) peut se faire sur toute l’image en transposant l’image sous forme d’une matrice avec Largeur x Hauteur lignes et 4 colonnes:
Il est possible de visualiser l’arbre avec l’outil SuperTree mais cela contient beaucoup d’information
from supertree import SuperTree # <- import supertree :)
super_tree = SuperTree(clf, X_train, y_train, ['Bleu', 'Vert', 'Rouge', 'NIR'], nom_classes2)
super_tree.show_tree()On peut voir que le nœud le plus haut utilise la bande proche-infrarouge pour séparer l’eau de la forêt comme première décision.
6.6 Méthodes paramétriques
Les méthodes paramétriques se basent sur des modélisations statistiques des données pour permettre une classification. Contrairement au méthodes non paramétriques, elles ont un nombre fixe de paramètres qui ne dépend pas de la taille du jeu de données. Par contre, des hypothèses sont faites a priori sur le comportement statistique des données. La classification consiste alors à trouver la classe la plus vraisemblable dont le modèle statistique décrit le mieux les valeurs observées. L’ensemble d’entraînement permettra alors de calculer les paramètres de chaque Gaussienne pour chacune des classes d’intérêt.
6.6.1 Méthode Bayésienne naïve
La méthode Bayésienne naïve Gaussienne consiste à poser des hypothèses simplificatrices sur les données, en particulier l’indépendance des données et des dimensions. Ceci permet un calcul plus simple.
from sklearn.naive_bayes import GaussianNB
gnb = GaussianNB()
y_pred = gnb.fit(X_train, y_train).predict(X_test)
print("Nombre de points erronés sur %d points : %d"
% (X_test.shape[0], (y_test != y_pred).sum()))Nombre de points erronés sur 200 points : 131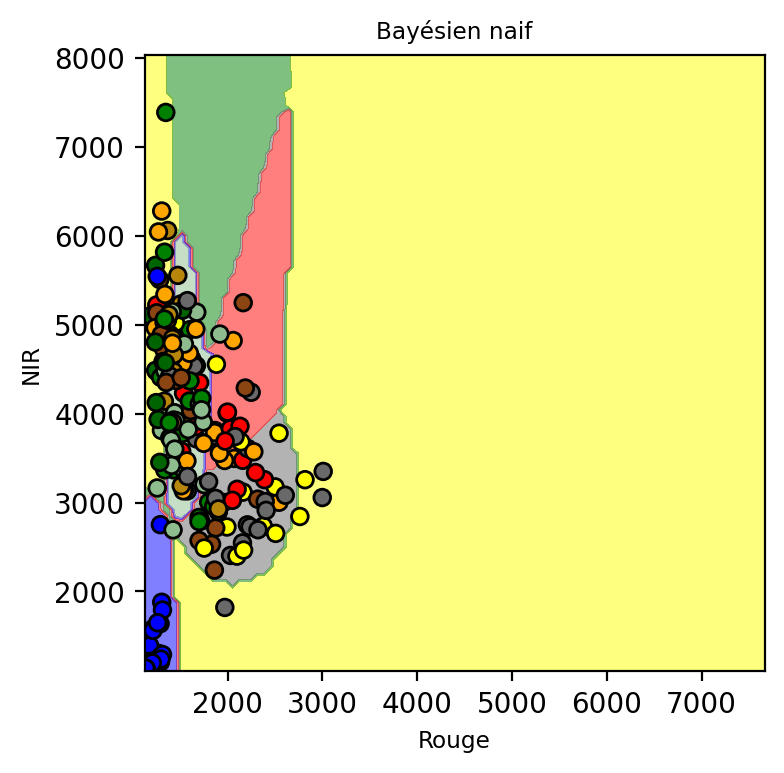
On observe que les frontières de décision sont beaucoup plus régulières que pour K-NN.
gnb.fit(X_train, y_train)
y_pred = gnb.predict(X_test)
print("Nombre de points misclassifiés sur %d points : %d"
% (X_test.shape[0], (y_test != y_pred).sum()))Nombre de points misclassifiés sur 200 points : 131De la même manière, la prédiction peut s’appliquer sur toute l’image:
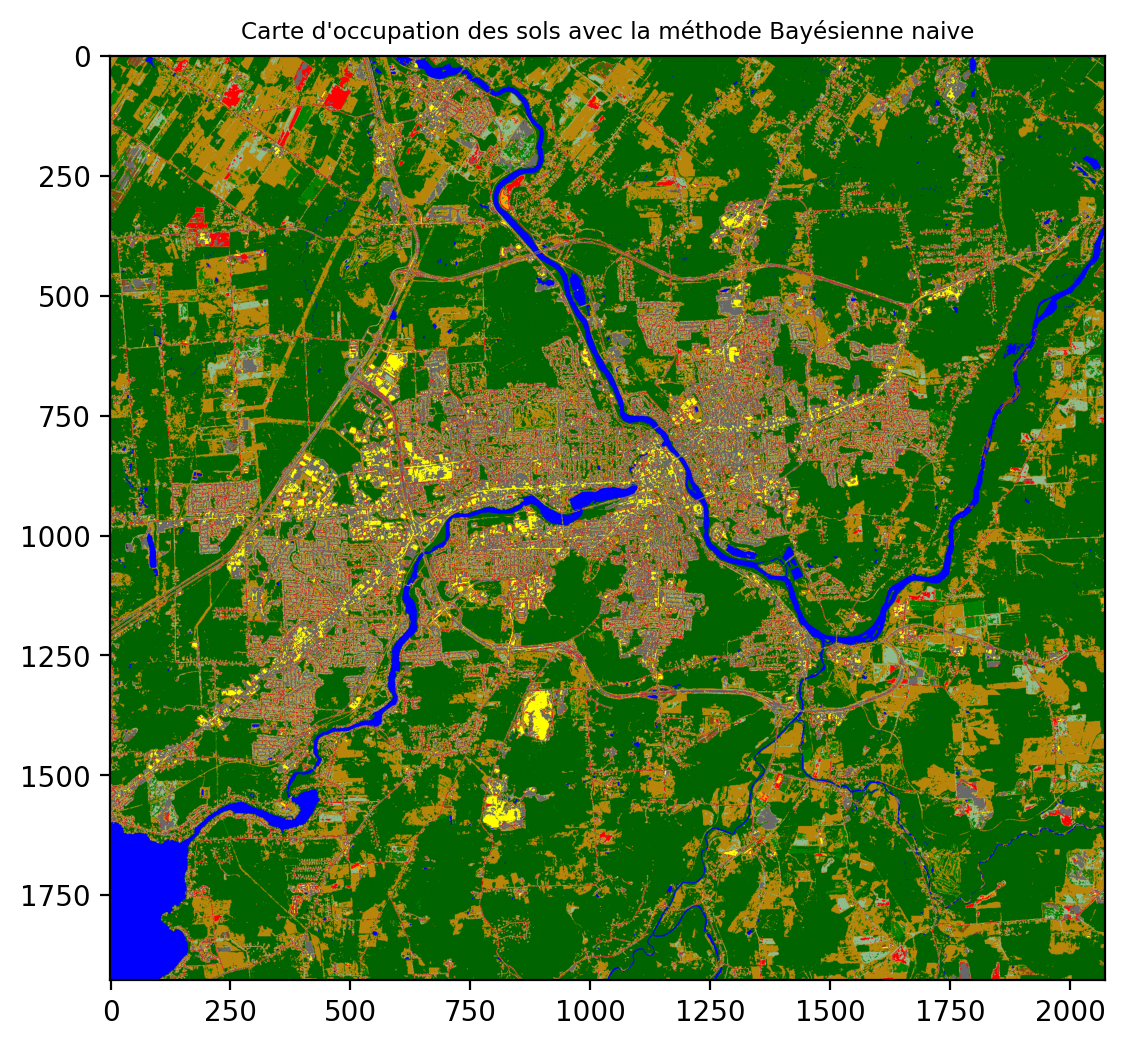
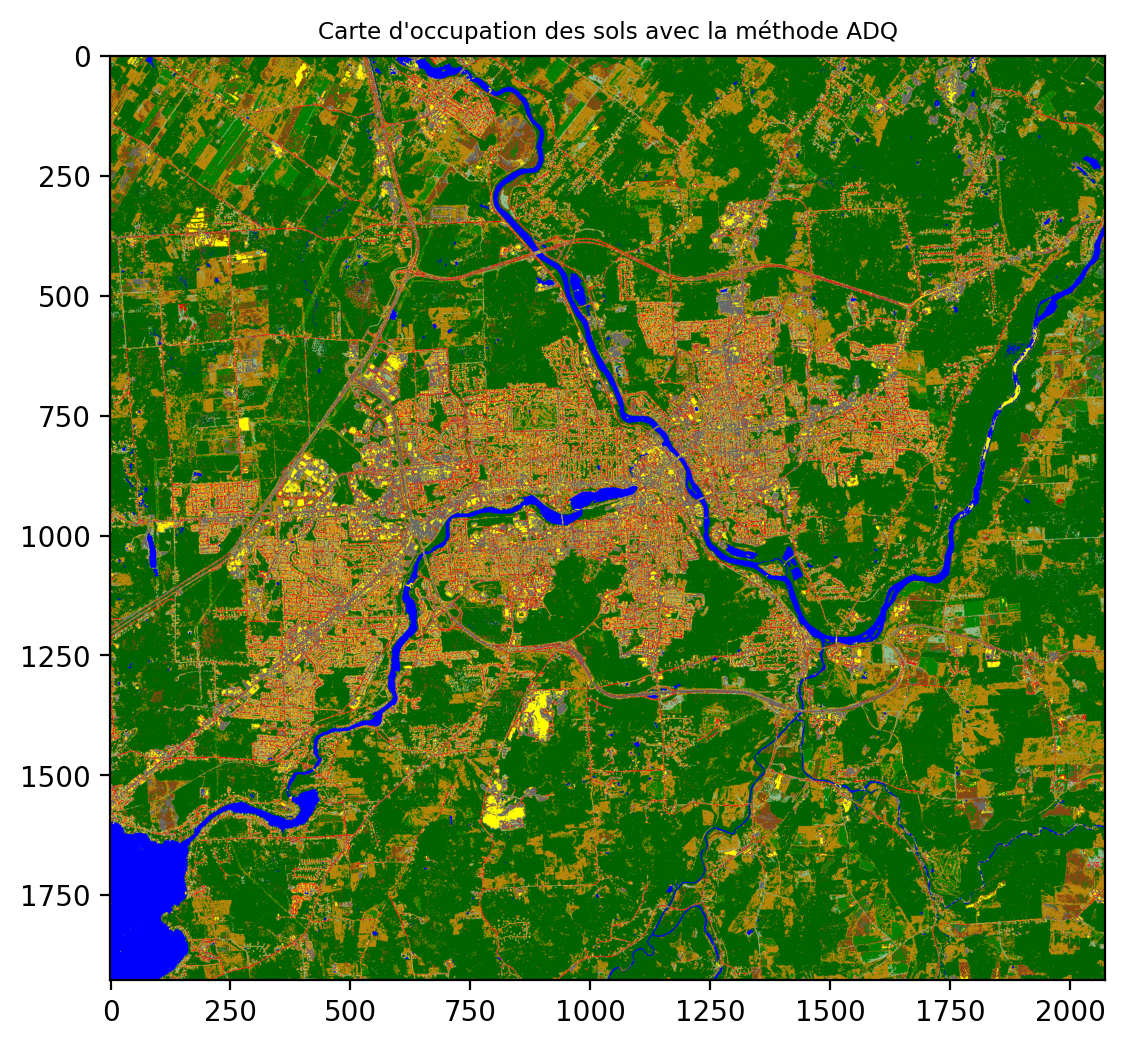
6.6.2 Analyse discriminante quadratique (ADQ)
L’analyse discriminante quadratique peut-être vue comme une généralisation de l’approche Bayésienne naive qui suppose des modèles Gaussiens indépendants pour chaque dimension et chaque point. Ici, on va considérer un modèle Gaussien multivarié.
qda = QuadraticDiscriminantAnalysis(store_covariance=True)
qda.fit(X_train, y_train)
y_pred = qda.predict(X_test)
print("Nombre de points misclassifiés sur %d points : %d"
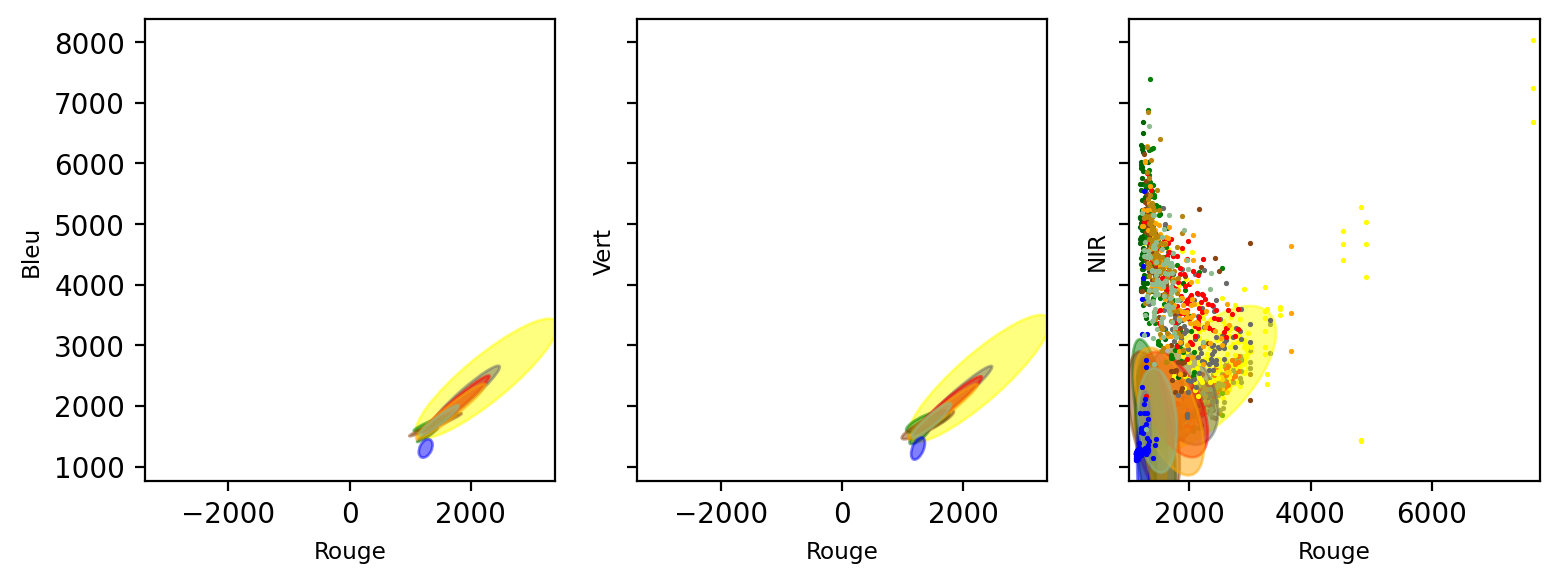
% (X_test.shape[0], (y_test != y_pred).sum()))Nombre de points misclassifiés sur 200 points : 124Les Gaussiennes multivariées peuvent être visualiser sous forme d’éllipses décrivant le domaine des valeurs de chaque classe:
De la même manière, la prédiction peut s’appliquer sur toute l’image: